
Abstract
We live in on-demand, on-command digital universe with data rapid reproducing by Institutions, Individuals and tools at very high rate. This data is categorized as “Big Data” due to its absolute Volume, Variety, Velocity and Veracity. Most of the data is partly structured, unstructured or semi structured and it is heterogeneous in nature. Due to its specific nature, Big Data is stored in distributed file system architectures. Hadoop and HDFS by Apache are widely used for storing and managing Big Data. Analyzing it, is a challenging task as it involves large distributed file systems which should be fault tolerant, flexible and scalable. Cloud computing plays a very vital role in protecting the data, applications and the related infrastructure with the help of policies, new technologies, controls, and big data tools. Moreover, cloud computing, applications of Big data, and its advantages are likely to represent the most promising new frontiers in science. The technology issues, like Storage and data transport are seem to be solvable in the near-term, but represent long term challenges that require research and new paradigms. Analyzing the issues and challenges comes first as we begin a collaborative research program into methodologies for big data analysis and design.
Keywords
Big Data, Cloud Computing and Map Reduce
I. Introduction
The term ‘Big Data’ appeared for first time in 1998 in a Silicon Graphics (SGI) slide deck by John Mashey with the title of “Big Data and the NextWave of Infra Stress”. It is the term for data sets so large and complicated that it becomes difficult to process using traditional data management tools or processing applications. The origin of the term ‘Big Data’ is due to the fact that we are creating a huge amount of data every day. At the KDD BigMine 12 Workshop Usama Fayyad in his invited talk presented amazing data numbers about internet usage, among them are the following: each day Google has more than 1 billion queries, Twitter has more than 250 million tweets per day, Per day Face book has more than 800 million updates, and YouTube has more than 4 billion views per day. Big Data is a heterogeneous mix of data both structured (traditional datasets –in rows and columns like DBMS tables, CSV’s and XLS’s) and unstructured data like PDF documents, e-mail attachments, images, manuals , medical records such as x-rays, ECG and MRI images, forms, rich media like graphics, video and audio, contacts, forms and documents. Businesses are primarily concerned with managing unstructured data, because about 80 percent of enterprise data is unstructured [1].
Google has introduced MapReduce [2] framework for processing large amounts of data on commodity hardware. Apache’s Hadoop distributed file system (HDFS) is evolving as a superior software component for cloud computing combined along with integrated parts such as MapReduce. Hadoop, which is an open-source implementation of Google MapReduce, including a distributed file system, provides to the application programmer the abstraction of the map and the reduce. Map Reduce by itself is capable for analyzing large distributed data sets; but due to the heterogeneity, velocity and volume of Big Data, it is a challenge for traditional data analysis and management tools [3][4]. For analysis of Big Data, database integration and cleaning is much harder than the traditional mining approaches [5]. Parallel processing and distributed computing is becoming a standard procedure which are nearly non-existent in RDBMS.
A. Importance of Big Data
The government’s emphasis is on how big data creates “value” – both within and across disciplines and domains. Value arises from the ability to analyze the data to develop actionable information. The survey of the technical literature [6] suggests five generic ways that big data can support value creation for organizations.
- Creating transparency by making big data openly available for business and functional analysis (quality, lower costs, reduce time to market, etc.)
- Supporting experimental analysis in individual locations that can test decisions or approaches, such as specific market programs.
- Assisting, based on customer information, in defining market segmentation at more narrow levels.
- Supporting Real-time analysis and decisions based on sophisticated analytics applied to data sets from customers and embedded sensors.
- Facilitating computer-assisted innovation in products based on embedded product sensors indicating customer responses.
B. Big Data Characteristics
One view, espoused by Gartner’s Doug Laney describes Big Data as having three dimensions: volume, variety, and velocity. Thus, IDC defined it: Big data technologies describe a new generation of technologies and architectures designed to economically extract value from very large volumes of a wide variety of data, by enabling high-velocity capture, discovery, and/or analysis.” [7] Two other characteristics seem relevant: value and complexity. We summarize these characteristics as given below.
1. Data Volume
Data volume measures the amount of data available to an organization, which does not necessarily have to own all of it as long as it can access it. As data volume increases, the value of different data records will decrease in proportion to age, type, richness, and quantity among other factors.
2. Data Velocity
Data velocity measures the speed of data creation, streaming, and aggregation. Ecommerce has rapidly increased the speed and richness of data used for different business transactions (for example, web-site clicks). Data Variety: Data variety is a measure of the richness of the data representation – text, images video, audio, etc.
3. Data Value
Data value measures the usefulness of data in making decisions. It has been noted that “the purpose of computing is insight, not numbers”. Data science is exploratory and useful in getting to know the data, but “analytic science” encompasses the predictive power of big data.
4. Complexity
Complexity measures the degree of interconnectedness (possibly very large) and interdependence in big data structures such that a small change (or combination of small changes) in one or a few elements can yield very large changes or a small change that ripple across or cascade through the system and substantially affect its behavior, or no change at all.
In addition to big data challenges induced by traditional data generation, consumption, and analytics at a much larger scale, newly emerged characteristics of big data has shown important trends on mobility of data, faster data access and consumption, as well as ecosystem capabilities [8].
In this paper, We studied a system that can scale to handle a large number of sites and also be able to process large and massive amounts of data. However, state of the art systems utilizing HDFS and Map Reduce are not quite enough/sufficient because of the fact that they do not provide required security measures to protect sensitive data. Moreover, Hadoop framework is used to solve problems and manage data conveniently by using different techniques.
C. Types of Big Data and Sources
There are two types of big data: structured and unstructured.
1. Structured Data
Structured Data are numbers and words that can be easily categorized and analyzed. These data are generated by things like network sensors embedded in electronic devices, smart phones, and global positioning system (GPS) devices. Structured data also include things like sales figures, account balances, and transaction data.
2. Unstructured Data
Unstructured Data include more complex information, such as customer reviews from commercial websites, photos and other multimedia, and comments on social networking sites. These data cannot easily be separated into categories or analyzed numerically. The explosive growth of the Internet in recent years means that the variety and amount of big data continue to grow. Much of that growth comes from unstructured data.

Fig. 1: Sources of Big Data
II. Security and Challenges
In certain domains, such as social media and health information, as more data is accumulated about individuals, there is a fear that certain organizations will know too much about individuals. Developing algorithms that randomize personal data among a large data set enough to ensure privacy is a key research problem. Perhaps the biggest threat to personal security is the unregulated accumulation of data by numerous social media companies. This data represents a severe security concern, especially when many individuals so willingly surrender such information. Questions of accuracy, dissemination, expiration, and access abound. Clearly, some big data must be secured with respect to privacy and security laws and regulations. International Data Corporation suggested five levels of increasing security [7]: privacy, compliance-driven, custodial, confidential, and lockdown. Further research is required to clearly define these security levels and map them against both current law and current analytics. For example, in Face book, one can restrict pages to ‘friends’. But, if Face book runs an analytic over its databases to extract all the friend’s linkages in an expanding graph, at what security level should that analytic operate? e.g., how many of an individual’s friends should be revealed by such an analytic at a given level if the individual (has the ability to and) has marked those friends at certain security levels? With the increase in the use of big data in business, many companies are wrestling with privacy issues. Data privacy is a liability, thus companies must be on privacy defensive. But unlike security, privacy should be considered as an asset; therefore it becomes a selling point for both customers and other stakeholders. There should be a balance between data privacy and national security. Meeting the challenges presented by big data will be difficult. The variety of data being generated is also expanding, and organizations capability to capture and process this data is limited. Current technology, architecture management and analysis approaches are unable to cope with the flood of data, and organizations will need to change the way they think about, plan, govern, manage, process and report on data to realize the potential of big data. In the distributed systems world, “Big Data” started to become a major issue in the late 1990‟s due to the impact of the world-wide Web and a resulting need to index and query its rapidly mushrooming content. Database technology (including parallel databases) was considered for the task, but was found to be neither well-suited nor cost-effective [9] for those purposes.
Google’s technical response to the challenges of Web-scale data management and analysis was simple, by database standards, but kicked off what has become the modern “Big Data” revolution in the systems world [10]. To handle the challenge of Web-scale storage, the Google File System (GFS) was created [11]. To handle the challenge of processing the data in such large files, Google pioneered its Map Reduce programming model and platform [3] [11]. This model, characterized by some as “parallel programming for dummies”, enabled Google developers to process large collections of data by writing two user-defined functions, map and reduce, that the Map Reduce framework applies to the instances (map) and sorted groups of instances that share a common key (reduce) similar to the sort of partitioned parallelism utilized in shared-nothing parallel query processing. Taking Google’s GFS and Map Reduce papers as rough technical specifications, open- source equivalents were developed, and the Apache Hadoop Map Reduce platform and its underlying file system (HDFS, the Hadoop Distributed File System) were born [3][12]. Popular languages include Pig from Yahoo! [13], Jaql from IBM [14], and Hive from Facebook [13]. Microsoft’s technologies include a parallel runtime system called Dryad and two higher-level programming models, Dryad LINQ and the SQLlike SCOPE language [15], which utilizes Dryad under the covers. Interestingly, Microsoft has also recently announced that its future “Big Data” strategy includes support for Hadoop [16].
The challenges of security in cloud computing environments can be categorized into network level, user authentication level, data level, and generic issues.
A. Network level
The challenges that can be categorized under a network level deal with network protocols and network security, such as distributed nodes, distributed data, Internode communication.
B. Authentication Level
The challenges that can be categorized under user authentication level deals with encryption/decryption techniques, authentication methods such as administrative rights for nodes authentication of applications and nodes, and logging.
C. Data Level
The challenges that can be categorized under data level deals with data integrity and availability such as data protection and distributed data.
D. Generic Types
The challenges that can be categorized under general level are traditional security tools, and use of different technologies.
III. Progress of Bigdata and Forecast to the Future
Cloud computing as an important application environment for big data has attracted tremendous attentions from the research community. Remarkable progress of big data networking has also been reported in this area. In this section, we studied the following topics: cloud resource management of big data and performance optimization of big data in Cloud Computing.
A. Overview and Resource Management
Agarwal et al. [17] focused on systems for supporting update heavy applications and ad-hoc analytics and decision support. Multi-tenant system model with different level of resource sharing is shown in Fig.2. Figure 2 depict representative forms of the challenging multi-tenant model and trade-offs associated with different forms of sharing. Since models share resources at different levels of abstraction, isolation guarantees can be achieved differently accordingly. Resource management plays a fundamental role in big data applications in the cloud. We next review important progress in this regard. A general introduction to resource management and allocation in multi-cluster clouds were introduced in [18]. [19] Introduces virtualization planning and cloud computing methods in IBM data center networking. Key operational challenges such as support cost-saving technologies, rapid deployment, support for mobile and pervasive access, development of enterprise-grade network design has been discussed extensively. Lu, Sifei et al [20] presented their work of a framework for cloud-based large-scale data analytics and virtualization; a case study on climate data of various scales were introduced too.
Specifically for reducing cooling energy cost for big data analytics cloud, a data-centric approach was introduced in [21]. Instead of relying on thermal-aware computational job placement/migration, the method in [21] takes a data-centric approach, which is now popular in big data applications. In sum, pervasive computing of big data in the cloud, computational resource and data complexity management, and energy consumption manipulations for big data in the cloud are fundamentally important aspects. The studied works have made logical progress in terms of system design and implementation, but much remains to be done with consideration of system validation in larger, real-world applications.
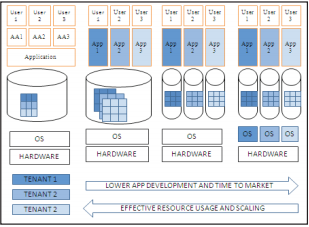
Fig. 2: Multi-Tenant Model: Left To Right Shared Table, Shared Database, Shared OS & Shared Hardware.
B. Performance Optimization
Performance optimization is yet another classic and important topic in cloud computing because appropriate optimization techniques will provide better application experiences with comparable or even less system resource consumption, compared to non-optimized cases. A dataflow-based performance analysis tool for big data cloud, i.e., Hitune, was presented in [22]. Hitune is shown to be effective in assisting users doing Hadoop performance analysis and system parameter tuning. A few interesting case studies on big data processing in cloud computing environment was depicted in [23]. Efforts of the Fijitsu laboratory are based on data store and complex event processing, as well as workflow description in distributed data processing. A recent online cost-minimization algorithm was depicted in [24]. The two online algorithms have achieved competitive cost reduction ratios. The Algorithms need to be further evaluated at larger and more competitive scales, e.g., data streaming applications with larger topologies. In sum, Hitune and the Fijitsu laboratory approaches have been focused on promoting user experiences by using fundamental big data techniques such as event processing and work flow description. Tools and case studies like this are informational and offer more choices to users. Moreover, online cost-minimizing as another promising direction has been proved to be effective in big data applications. We expect a lot more scalable and efficient algorithms to be proposed in the near future.
C. Future Challenges
There are many future important challenges in Big Data management and analytics that arise from the nature of data: large, diverse, and evolving. These are some of the challenges that researchers and practitioners will have to deal during the next years:
1. Analytics Architecture
It is not clear yet how an optimal architecture of an analytics system should be to deal with historic data and with real-time data at the same time. An interesting proposal is the Lambda architecture of Nathan Marz. The Lambda Architecture solves the problem of computing arbitrary functions on arbitrary data in real time by decomposing the problem into three layers: the batch layer, the serving layer, and the speed layer. It combines in the same system Hadoop for the batch layer, and Storm for the speed layer.
2. Statistical Significance
It is important to achieve significant statistical results, and not be fooled by randomness. AsEfron explains in his book about Large Scale Inference it is easy to go wrong with huge data sets and thousands of questions to answer at once.
3. Distributed Mining
Many data mining techniques are not trivial to paralyze. To have distributed versions of some methods, a lot of research is needed with practical and theoretical analysis to provide new methods.
IV. Advancements & Conclusion
Streaming algorithms [25] represent an alternative programming model for dealing with large volumes of data with limited computational and storage resources. Stream processing is very attractive for working with time-series data (news feeds, tweets, sensor readings, etc.), which is difficult in MapReduce (once again, given its batch-oriented design). Another system worth mentioning is Pregel [26], which implements a programming model inspired by Valiant’s Bulk Synchronous Parallel (BSP) model. Pig [14], which is inspired by Google [11], can be described as a data analytics platform that provides a lightweight scripting language for manipulating large datasets. Similarly, Hive [27], another open-source project, provides an abstraction on top of Hadoop that allows users to issue SQL queries against large relational datasets stored in HDFS. Therefore, the system provides a data analysis tool for users who are already comfortable with relational databases, while simultaneously taking advantage of Hadoop’s data processing capabilities [28]. MapReduce is certainly no exception to this generalization, even within the Hadoop/HDFS/ MapReduce ecosystem; it is already observed the development of alternative approaches for expressing distributed computations. For example, there can be a third merge phase after map and reduce to better support relational operations. Join processing mentioned n the paper can also tackle the Map Reduce tasks effectively. Big data is the “new” business and social science frontier. The amount of information and knowledge that can be extracted from the digital universe is continuing to expand as users come up with new ways to massage and process data. Moreover, it has become clear that “more data is not just more data”, but that “more data is different”. “Big data” is just the beginning of the problem. Technology evolution and placement guarantee that in a few years more data will be available in a year than has been collected since the dawn of man. If Facebook and Twitter are producing, collectively, around 50 gigabytes of data per day, and tripling every year, within a few years (perhaps 2-4) we are indeed facing the challenge of “big data becoming really big data”. In this work, we have done in-depth reviews on recent efforts dedicated to big data and big data networking. We have reviewed the progresses in fundamental big data technologies, important aspects of big data networking, and security in cloud computing such as new challenges and opportunities, resource management and performance optimizations are also introduced and discussed with independent viewpoints.
This paper initiates a collaborative research effort to begin examining big data issues and challenges. We identified some of the major issues in big data storage, management, and processing. We also identified some of the major challenges – going forward – that we believe must be addressed within the next decade. Our future research will concentrate on developing a more complete understanding of the issues associated with big data, and those factors that may contribute to a need for a big data analysis and design methodology. We will begin to explore solutions to some of the issues that we have raised in this paper through our collaborative research effort.
V. Acknowledgements
We would like to express our cordial thanks to Sri. CA. Basha Mohiuddin, Chairman, Smt. Rizwana Begum-Secretary and Sri. Touseef Ahmed-Vice Chairman – , Dr.M.Anwarullah –Principal, Vidya Group of Institutions, Hyderabad for providing moral support, encouragement and advanced research facilities. Authors would like to thank the anonymous reviewers for their valuable comments. And they would like to thank Dr.V. Vijaya Kumar, Anurag Group of Institutions for his invaluable suggestions and constant encouragement that led to improvise the presentation quality of this paper.
References
[1] Agrawal, Amr El Abbadi et al.,“Big data and cloud computing: current state and future opportunities”, Proceedings of the 14th International Conference on Extending Database Technology.ACM, 2011
[2] Apache Hive, [Online] Available: http://hive.apache.org.
[3] Brad Brown, Michael Chui, James Manyika,“Are you ready for the era of big data”, McKinsey Quaterly, Mckinsey Global Institute, October 2011.
[4] Carlos Ordonez,”Algorithms and Optimizations for Big Data Analytics: Cubes”, Tech Talks, University of Houston, USA.
[5] Cisco White Paper,”Cisco Visual Networking Index: Global Mobile Data Traffic Forecast Update 2010-2015″, [Online] Available: http://newsroom.cisco.com /ekits/Cisco_VNI_ Global_Mobile_Data_Traffic_Forecast_2010_2015.pdf.
[6] Dai, Jinquan, et al.,“Hitune: dataflow-based performance analysis for big data cloud”, Proc. of the 2011 USENIX ATC (2011), pp. 87-100. [Online] Available: https://www.usenix. org/legacy/event/atc11/tech/final_files/Dai.pdf.
[7] Dryad- Microsoft Research, [Online] Available: http:// research.microsoft.com/en-us/projects/dryad
[8] DunrenChe, MejdlSafran, ZhiyongPeng,”From Big Data to Big Data Mining: Challenges, Issues, and Opportunities”, DASFAA Workshops 2013, LNCS 7827, pp. 1–15, 2013.
[9] DunrenChe, MejdlSafran, ZhiyongPeng,”From Big Data to Big Data Mining: Challenges, Issues, and Opportunities”, DASFAA Workshops 2013, LNCS 7827, pp. 1–15, 2013.
[10] Girola, Michele, et al.,“IBM Data Center Networking: Planning for virtualization and cloud computing”, GOOGLE/ IP. COM/IBM Redbooks (2011). [Online] Available: http:// www.redbooks.ibm.com/redbooks/pdfs/sg247928.pdf. .
[11] GrzegorzMalewicz, Matthew H. Austern, Aart J. C. Bik, James C.Dehnert, Ilan Horn, NatyLeiser, Grzegorz Czajkowski, Pregel, “A System for Large-Scale Graph Processing”, SIGMOD‟10, June 6–11, 2010, pp. 135-145.
[12] IBM-What.is.Jaql, [Online] Available: http://www.ibm.com/software/data/ infosphere /hadoop/jaql.
[13] Information System & Management, ISM Book, 1st Edition 2010, EMC2, Wiley Publishing.
[14] J. Dean, S. Ghemawat,“MapReduce: Simplified data processing on large clusters”, In USENIXSymposium on Operating Systems Design and Implementation, San Francisco, CA, Dec. 2004, pp. 137–150.
[15] Jefry Dean, Sanjay Ghemwat,”Mapreduce: A Flexible Data Processing Tool”, Communications of the ACM, Vol. 53, IJCST Vol. 6, Issue 2, April – June 2015 ISSN : 0976-8491 (Online) | ISSN : 2229-4333 (Print) 102 International Journal of Computer Science And Technology www.ijcst.com Issuse 1, January 2010, pp. 72-77.
[16] Jefry Dean, Sanjay Ghemwat,”Mapreduce: Simplified Data Processing on Large Clusters”, Communications of the ACM, Vol. 51 pp. 107–113, 2008.
[17] Ji, Changqing, et al.,“Big data processing in cloud computing environments”, Pervasive Systems, Algorithms and Networks (ISPAN), 2012 12th International Symposium on. IEEE, 2012.
[18] Kaushik, Rini T., Klara Nahrstedt.,“T: A data-centric cooling energy costs reduction approach for big data analytics cloud”, Proceedings of the International Conference on High Performance Computing, Networking, Storage and Analysis. IEEE Computer SocietyPress,2012. [Online] Available: http://conferences.computer.org/sc/2012/papers/1000a037. pdf
[19] Lakew, Ewnetu Bayuh,”Managing Resource Usage and Allocations in Multi-Cluster Clouds 2013, [Online] Available: http://www8.cs.umu.se/~ewnetu/papers/lic.pdf
[20] Lu, Sifei, et al.,“A framework for cloud-based large-scale data analytics and visualization: Case study on multiscale climate data”, Cloud Computing Technology and Science (CloudCom), 2011 IEEE Third International Conference IEEE,2011.
[21] MarcinJedyk, MAKING BIG DATA, SMALL,”Using distributed systems for processing, analysing and managing large huge data sets”, Software Professional’s Network, Cheshire Data systems Ltd.
[22] PIG Tutorial, YahooInc., [Online] Available: http://developer. yahoo.com/hadoop/tutorial/pigtutorial.html. [23] Ren, Yulong, Wen Tang,“A Service Integrity Assurance Framework For Cloud Computing Based On Mapreduce”, Proceedings of IEEE CCIS2012. Angzhou: 2012, pp 240 –244, Oct. 30 2012-Nov. 1 2012.
[24] S. Ghemawat, H. Gobioff, S. Leung,“The Google File System”, In ACM Symposium on Operating Systems Principles, Lake George, NY, Oct 2003, pp. 29-43.
[25] Stephen kaisler, F.Armour, J.Alberto Espinosa, William Money,“Big data:Issues and Challenges moving Forward”, 46th HICSS, US. 1530-1605/12, 2013.
[26] Tyson Condie, Neil Conway, Peter Alvaro, Joseph M. Hellerstein, JohnGerth, Justin Talbot, Khaled Elmeleegy, Russell Sears,”Online Aggregation and Continuous Query support in MapReduce”, SIGMOD‟10, June 6–11, 2010, Indianapolis, Indiana, USA.
[27] Windows.Azure.Storage. [Online] Available: http://www. microsoft.com/windowsazure/features/storage.
[28] Zhang, Linquan, et al.,“Moving Big Data to The Cloud: An Online Cost-Minimizing Approach”, IEEE JOURNAL ON SELECTED AREAS IN COMMUNICATIONS 31.12 (2013): [Online] Available: http://i.cs.hku.hk/~fcmlau/papers/info13-lq- .pdf.
 Dr. J. Sasi Kiran Graduated in B.Tech [EIE] from JNTU Hyd. He received Masters Degree in M.Tech [CSE] from JNT University, Hyderabad. He received Ph.D degree in Computer Science from University of Mysore, Mysore. At Present he is working as Professor in CSE and Dean – Administration in Vidya Vikas Institute of Technology, Chevella, R.R. Dist Telangana State, India. His research interests include Image Processing, Data Mining and Network Security. He has published 39 research papers till now in various National, International Conferences, Proceedings and Journals. He has received best Teacher award twice from Vidya Group, Significant Contribution award from Computer Society of India and Passionate Researcher Trophy from Sri. Ramanujan Research Forum, GIET, Rajuhmundry, A.P, India.
Dr. J. Sasi Kiran Graduated in B.Tech [EIE] from JNTU Hyd. He received Masters Degree in M.Tech [CSE] from JNT University, Hyderabad. He received Ph.D degree in Computer Science from University of Mysore, Mysore. At Present he is working as Professor in CSE and Dean – Administration in Vidya Vikas Institute of Technology, Chevella, R.R. Dist Telangana State, India. His research interests include Image Processing, Data Mining and Network Security. He has published 39 research papers till now in various National, International Conferences, Proceedings and Journals. He has received best Teacher award twice from Vidya Group, Significant Contribution award from Computer Society of India and Passionate Researcher Trophy from Sri. Ramanujan Research Forum, GIET, Rajuhmundry, A.P, India.
 Ms.M.Sravanthi Graduated in B.Tech [CSE] from JNTU Hyd.She received Masters Degree in M.Tech [CSE] from JNTU Hyd. Her interested areas are Cloud Computing, Image Processing and Networking. Currently, she is working as an Associate Professor in Vidya Vikas Institute of Technology.
Ms.M.Sravanthi Graduated in B.Tech [CSE] from JNTU Hyd.She received Masters Degree in M.Tech [CSE] from JNTU Hyd. Her interested areas are Cloud Computing, Image Processing and Networking. Currently, she is working as an Associate Professor in Vidya Vikas Institute of Technology.

Ms. K. Preethi Graduated in B.Tech [CSE] from JNTU Hyd.She received Masters Degree in M.Tech [CSE] from JNTU Hyd. Her interested areas are Cloud Computing, Distributed Systems, Data Mining. Currently, she is working as an Assistant Professor in Vidya Vikas Institute of Technology.
 Mrs. M. Anusha Graduated in B.Tech [CSE] from JNTU Hyd. She received Masters Degree in M. Tech from JNTU Hyd. Her Interested areas are Wireless Sensor Networks, Computer Organization, Network Security and Cryptography. Currently, she is working as an Associate Professor in Vidya Vikas Institute of Technology. She has published research papers in various National, International conferences, proceedings and Journals.
Mrs. M. Anusha Graduated in B.Tech [CSE] from JNTU Hyd. She received Masters Degree in M. Tech from JNTU Hyd. Her Interested areas are Wireless Sensor Networks, Computer Organization, Network Security and Cryptography. Currently, she is working as an Associate Professor in Vidya Vikas Institute of Technology. She has published research papers in various National, International conferences, proceedings and Journals.
Authors: Dr. Jangala. Sasi Kiran, M.Sravanthi, K.Preethi, M.Anusha