
The Information Age, with its even more clever methods for gathering data, is putting the screws to scientists across a wide range of disciplines. Astronomers, geologists; medical researchers – all must contend with veritable avalanches of data produced by the latest in data-gathering instruments. Gone are moments of quiet reflection and leisurely collegial chats. Now, it’s work, work, work as researchers hunt through mountains of facts for that one elusive correlation that could set their corner of the scientific world on its ear.
Ask the astronomers at the California Institute of Technology’s Palomar observatory who are busy conducting a three-color photographic survey of the entire northern sky that will generate some 3 terabytes of data – enough information to fill 6 million books. Ask the geologists at Brown University on the Magellan Science Team who are sorting through 30,000 radar images to catalog perhaps 1 million small volcanoes on the surface of Venus. Ask the poor souls associated with the NASA Earth Observing System Synthetic Aperture Radar Satellite who will contend with 50 Gbytes of remote sending data per hour, around the clock, when that system is operational.
“The total data is enormous, just on a daily basis,” says Brown research geologist Larry Crumpler, speaking of the orbital platforms being developed for Earth-observing systems at NASA and elsewhere. “You’d like to look at this data every day, since you’re getting it that often, but there’s just too much. If you had a year, maybe you could look through one day’s data set.
JPL to the rescue
Working with his colleagues at the Jet Propulsion Lab’s Machine Learning Systems Group, Usama Fayyad has developed a series of intelligent, trainable image-analysis tools for helping researchers manage the deluge of image data engulfing them. Their Sky Image Cataloging and Analysis Tool (Skicat) uses a decision-tree approach to classify the many millions of stars, galaxies, and quasars coming out of the Palomar sky survey – at levels tenfold fainter, and light year faster, than any human could do. Their JPL Adaptive Recognition Tool (Jartool), an even more ambitious project because it involves learning from data sets that incorporate much greater uncertainty, classifying the several hundred thousands of small volcanoes on Venus.
Skicat will help astronomers understand fundamental aspects of the universe, answering questions about the large-scale distribution of galaxies, the rate of their evolution, and the structure of our own galaxy. By providing information about the number and distribution of volcanoes on Venus, Jartool gives geologists valuable insights into the formation and thickness of that planet’s crust.
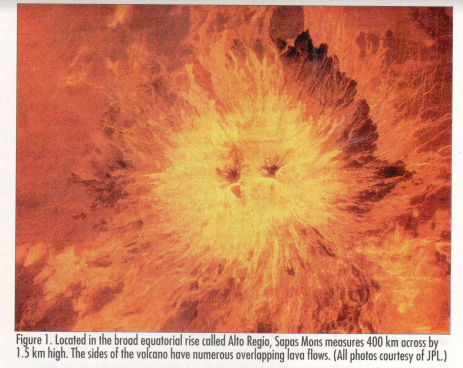
“Planets, like living beings, have internal heat,” says Jayne Aubule, Crumpler’s partner on the Venus project. Volcanism is of the ways a planet gets rid of internal heat. (Figure 1 shows an example of a large volcano.) “There’s a correlation between the size of a plant, how long it’s geologically active, and how long it takes it to get rid of its internal heat. By understanding what’s happening on Venus, we can bring that information back to Earth to help understand our own planet.”
These image-analysis tools have potential application to a wide range of other domains as well: cell counting for medical image analysis, face recognition in video images for security, purposes, remote sensing data analysis, and parts inspection and defect detection in manufacturing setting.
Counting stars
Astronomers at Caltech have nearly completed the Second Palomar Observatory Sky Survey (POSS-II), which will provide comprehensive coverage of the northern celestial hemisphere. Using their 48-inch Oschin Schmidt telescope, they will ultimately collect 3,000 photographic plates, each digitized into a 23,040X23,040 pixel image, representing 2 billion stars, 50 million galaxies, and over 100,000 quasars.
The problem is not so much in gathering data, however, as in using it. Fayyad estimates that only 5 to 10% of the data from an earlier sky urvey, POSS-I, done four decades ago, was ever used, “and that by astronomers who were only interested in certain parts of the sky,” George Djorgevski, head of Caltech’s team of astronomers, wanted to prevent that waste this time around by getting the data on-line. So he approached Fayyad for help not only in automating the cataloging process, which did not involve addressing any new problems, but also in classifying the many faint objects in the survey, which did.
“Because that second aspect would allow us to use machine-learning techniques, and because of the NASA funding we have at JPL – which basically is geared toward finding problems in science data analysis that require artificial intelligence and building systems to solve them – there was a match,” says Fayyad. “We could support them at both-ends, both in building the whole system and in solving the problems that involved AI technology.”
Saving time on the mountain. “People have been staring at the sky for thousands of years,” says Fayyad, who also teaches AI courses at the University of Southern California. It’s unlikely that there will be any new discoveries of a commonplace occurrence. “If there is a new discovery, it’s going to be a set of very rare objects, meaning that in millions of data points, there may only a few hundred of them.”
The problem is that no human mind, no matter how well trained and disciplined, can assimilate millions of bits of information in any meaningful way. “A scientist would look at a few hundred or a few thousand, and then might notice something weird and pursue it.” But that subtle patterns in the millions and billions of objects in the sky survey would likely go unnoticed.
By focusing the clustering algorithms developed to work on Skicat-generated catalogs on some of the faintest objects with a high likelihood of being quasars – an especially important object for astronomers. Skicat reduces the scans into object catalogs, classifies them, and then allows for easy access to the data. Astronomers can then follow up with spectroscopy or by making observations on the mountains, observing with a very narrow field of view and integrating over a long period of time, to determine which are actually quasars. The algorithms cut down human observation time by one order of magnitude from previous classification attempts.
“That’s the key,” says Fayyad. “Observation time is expensive. You need an astronomer who sits up all night playing with the telescope, staring at one image and then another.” Cutting observation time so drastically means that the Skicat algorithms that the Skicat algorithms generate candidates with a low false-alarm rate.
“Skicat has allowed us to find these objects in a very short amount of time in a very efficient manner,” agrees Julia Kenefick, a graduate student on Djorgovski’s team, who is in charge of the quasar survey and who will assume a post doctoral position at Ohio State next year. “It has allowed us to do his project in a year when other projects using similar techniques might have taken two or three times as long.”
Learning and clustering algorithms. The JPL learning algorithms – GID to the power of 3*, OBTree, and Ruler to the power of four – produce decision trees and classification rules from training sets of astronomer-classified sky data. The training sets were derived by matching charge-coupled device data, having higher resolutions and reaching to greater magnitudes, with a subset of the plate data. The CCD images come from Palomar’s 60-inch telescope and allow for much more reliable classification.
Fayyad’s team chose the decision-tree approach over neural nets because it’s easier for domain experts to understand, simpler – no need, for example, for specifying such parameters as the size of the neural net – and allows for much faster training time.
“What you really want is algorithms that automatically go through the data and do unsupervised learning, or clustering,” says Fayyad, winner of JPL’s 1993 Lew Allen Award for Excellence. “That way, you’ll find a group of objects that are strange in some sense, sitting off to the side somewhere” – here he’s talking about parameter or observational space, not sky space, as astronomers have little interest in looking at the actual photographic plates.
“They could be pure noise, or problems with observations, or they could actually be new discoveries.” If the latter, astronomers could then observe each new object very carefully, and synthesize a theory as to why is has clustered separately.
Clusters of weirdos. Current attempts to extend the capabilities of the Skicat algorithms include finding clever, quick ways to isolate seeds of clusters in the data, for avoiding global searches, and, second, developing ways of iteratively constructing samples of the oddball objects, or minority classes, that would get lost in random sampling. To do that, the astronomer would take a sample of a few thousand objects. It doesn’t matter that the minority classes would get lost in this sampling, because this is simply a model – which is a bunch of clusters. “Now that we’ve built the model, we can feed millions of examples through it, because classification isn’t a very intensive operation.”
This feeding through involves assigning various probabilities to each sample” whether an object belongs strongly to a particular cluster, or doesn’t belong to any cluster. “What we have then is a way to distinguish these guys that fit in the initial clusters from those that don’t fit – the misfits.” By collecting only the misfits, he will slowly build a population of only the weird objects. “When we have enough of them, we can do clustering on just the weirdos to determine which ones represent strong clusters.”
Ten new quasars
Applying these new tools on this vast data set can provide astronomers with vital clues about the formation of early galaxies and the composition of the intergalactic medium. Especially important here are quasars, the brightest objects in the universe. Because they can be observed at such great distances, quasars provide important clues about the formation of the first galaxies, and the structure of the early universe. “We see quasars from a time when the universe was only 10% of its present age,” says Djorgovski.
Discrepant data. Previous observational studies similar to POSS-II provided data that suggested that there is an excess number of faint galaxies relative to simple models of their evolution. These old data seemed to indicate that the rate of galaxy formation was unexpectedly high in the recent cosmic past.
“It wasn’t at all clear, however, to what extent the previous observations represented true observation, or were simply the result of serious systematic error,” says Nick Weir, a member of Djorgovski’s team who now performs financial modeling for Goldman Sachs on Wall Street. “It’s very easy for small systematic errors in galaxy classification, and likewise the measurement of the brightness of the galaxies, to have a significant effect.”
Already, in its first use, Skicat has shown that the data is more consistent with current theory. That’s because it enables astronomers to properly detect and classify data points at much fainter levels than ever before. “Skicat provides the best available – deepest, most accuate, most uniform – database with which to match up optical identification with x-rays and radio sources discovered from other surveys,” Weir says.
High-redshift quasars. To date, Skicat has isolated 10 new high-redshift quasars. (Redshift is a measure of the distance of space objects from Earth; the higher the redshift value, the more distant the object, hence the farther back in time.) “In less than a year, and with only a few nights of telescope time, we discovered the same number of high-redshift quasars as the previous group had done at Palomar over many years – with maybe a factor of 10 or 20 times our investment in observing time,” says Djorgovski, who expects to see an order of magnitude jump in the number of identified high-redshift quasars by project’s end.
Because the light from these early quasars must pass through gaseous clouds in the empty spaces between galaxies, they can help astronomers determine the composition of those clouds. Knowing which and how much metal those clouds contain, for instance, gives astronomers a feel for star formation rates over time. “Metals are dispersed back into the intergalactic medium as stars are formed,” says Weir. “And these high-redshift quasars gives us a longer time history.”
Processing bottlenecks. The sky survey is about to wrap up. The big bottleneck, according to Fayyad, has been the digitizing of the photographic plates in the high-resolution scanner at the Space Institute Science Center in Baltimore. Now that they’re getting the plates back at a decent rate, the Skicat processing becomes a second bottleneck.
“It takes about 12 hours a process a plate, which is about half a million objects,” says Fayyad, who is cochairing the First International Conference on Knowledge Discovery and Data Mining (KDD-95) this August at the International Joint Conderence on Artificial Intelligence in Montreal. “The saving grace is that this is completely and trivially parallizable. If we had 10 Sun workstations doing the work, it would go 10 times faster.”
Venus unsheathed
Because the problem it attempts to solve is so much harder, Jartool is a much more difficult and potentially more useful project than Skicat. With Skicat, the astronomers could label objects in the training set with a high degree of assurance: they knew a galaxy when they saw one, and the CCD images gave them an exceedingly clear view. Not so with Jartool. The surface of Venus is shrouded in clouds, so the geologists attempting to label the small volcanoes actually look at sets of pixels from synthetic aperture radar images.
“Nobody’s been to Venus, so we don’t really have ground proof,” say Fayayd, who developed Jartool with Pietro Perona and Michael Burl. “So the labels scientists give us aren’t very reliable. If you compare on scientists against the same scientist a year from now labeling the same image, you’ll get significant differences,” says Smyth. Crumpler and Aubele put this error rate at up to 20%.
“It’s saying that if all you’re given is pixels and the labels on pixels, can you automatically learn to find objects?” says Fayyad. But that’s also its beauty, because “it will fit into the grander vision of having a tool that will allow your general user to walk up to a huge database, bring up some examples, and have the system search for ‘like’ objects.”
Sister planets. The Magellan probe orbited Venus every 3.5 hours for four Venus years (each equal to 243 Earth days) in nearly polar orbits, during which it collected twice the digital imaging data collected from all other US planetary missions combined. The Magellan data set for Venus covers 98% of the planet at a high enough resolution so that each pixel represents about 75 square meters, or roughly the size of a football field. In many ways, that makes the data set more complete than anything available for Earth, especially since so much of Earth’s surface is covered by water.
“ Venus turns out to be as dynamic geologically as Earth, and as complex,” says Aubule, a research geologist who spends much of her time as program manager of the Rhode Island Space Grant program, a nationwide organization designed to use space exploration as a way getting school children interested in basic science. “Venus has a lot of volcanoes, mountain ranges similar to the Himmalayas, rifts, valleys, what look like earthquake fault lines or structure lines – all kinds of geological phenomena that we need to quickly understand.”
Venus turns out to be as dynamic geologically as Earth, and as complex,” says Aubule, a research geologist who spends much of her time as program manager of the Rhode Island Space Grant program, a nationwide organization designed to use space exploration as a way getting school children interested in basic science. “Venus has a lot of volcanoes, mountain ranges similar to the Himmalayas, rifts, valleys, what look like earthquake fault lines or structure lines – all kinds of geological phenomena that we need to quickly understand.”
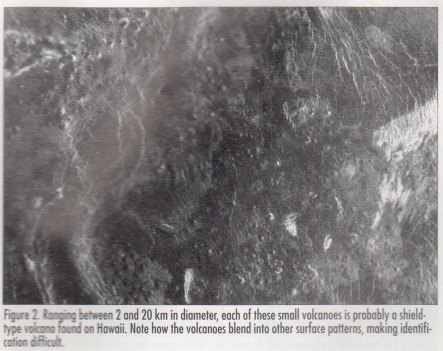
Because the surface of Venus contains no water, these features have suffered little erosion, providing a clear look at the geological record of the surface than could ever be developed for Earth. Even the fact that they must use radar images has worked to Crumpler and Aubele’s advantage. The radar images for the entire planet all have the same incidence angles, or look directions, so Jartool doesn’t have to deal with changed in those parameters. Figure 2 and 3 shows examples of the kinds of features they are interested in cataloging.
Three components. Jartool is based on three machine-learning components. The focus-of-attention stage automatically produces and aggressive filter that detects most targets, allowing a high false-alarm rate. The feature-learning stage use singular value decomposition of the training pixels to extract a set of features onto which the FOA set will be projected.
“You have to project this data from the high-dimensional pixel space down to a low-dimensional feature space, which preserves all important information,” says Fayyad. Humans do that all the time, as when we look at a wall that our brain encodes as a single entity. “Imagine if your brain had to deal with every little detail, every variation of paint tone and color. You’d probably go nuts just dealing with one wall.”
The third component, the classifier, then automatically learns to distinguish between true detections and false alarms. At that point, you can ship the results off to a catalog where they’re available for analysis.
Clustering volcanoes. So far in examining their Venus data, the geologists have noted that the small volcanoes on its surface tend to cluster in groups of 10 to 100 volcanoes in areas of roughly 100 to 150 km across. Why that happens, they’re not yet sure.
“The analogy is the small volcanoes on the sea floors of Earth,” says Crumpler.
“There are an extreme number of these small, low volcanoes that are very similar in their overall morphology to those on Venus.” Why the similarity is again an enigma.
What’s in it for us?
Such puzzles, though, can quickly become relevant to the more earthbound among us. The term greenhouse effect, for instance, was originally coined for Venus. “When we realized that carbon dioxide was causing this effect, we brought that knowledge home to Earth,” says Aubele. “We began to say, ‘Hey, wait a minute! Maybe we should start monitoring our CO2 levels here.”
Fayayd has been attending and conducting workshops around the US to transfer these machine-learning techniques to new technologies. Medical imaging, airport security, surveillance, an especially flexible manufacturing applications all could benefit. JPL has ongoing projects with General Motors, which wants to develop rules from its car repairs database, and AT&T, which is interested in tracking down potential network problems before they happen.
By: Dick Price
Source: IEEE EXPERT INTELLIGENT SYSTEMS & THEIR APPLICATIONS Volume 10, Issue 4